Berichte
Problem der Texterkennung von Fraktur gelöst
Scannen mit Texterkennung gehört zur Standardausrüstung von PCs. Doch Frakturschriften erwiesen sich bisher als resistent. Die OCR-Software "FineReader XIX" hat das Problem gelöst. Wir haben sie getestet.
Von Peter Stocker, Historisch-Kritische Gottfried Keller-Ausgabe (HKKA)
20. Februar 2005
FineReader XIX beruht auf der Texterkennungsoftware FineReader (Version 7). Die Namenserweiterung für dieses neue Produkt von ABBYY ist klug gewählt. Wer sich mit Drucken aus dem 19. Jahrhundert beschäftigt, hat es häufig und besonders in der deutschen Sprache mit Frakturschriften zu tun.
In solchen Fällen war bisher der Einsatz von OCR ('optical character recognition') nicht möglich. Die Gründe liegen in der Schrift selbst. Zeichen wie diejenigen für die Kleinbuchstaben von F und langem S sind sich zu ähnlich und werden notorisch verwechselt.
Charakteristisch für Fraktur ist ausserdem der kantige, 'gebrochene' Schnitt der Schriftzeichen und die wechselnde Breite der Strichkontur. Die Buchstaben sind zusammengesetzt aus schwach konturierten, 'fetten' Segmenten (v.a. bei vertikalen 'Schäften'), aus feiner konturierten Segmenten (v.a. bei Verbindungsstrichen) und aus Segmenten mit wechselnder Kontur (v.a. bei geschwungenen 'Schäften'). Für das Auge ergibt sich ein markant strukturiertes und zugleich fliessendes Druckbild. Für die Texterkennung aber wird dadurch schon die grundlegende Identifikation von Einzelzeichen und Zeichengrenzen zum Problem. Bestimmte Zeichenfolgen wie "un", "nu" oder "mn" werden fehleranfällig.
Charakteristisch sind auch Schnörkel und Verzierungen wie die sogenannte 'Elefantenrüssel' am Kopf von 'Schäften'. Was als Schmuck gedacht ist, wird in der Texterkennung zum Störfaktor, der das saubere Ausfiltern des durch Papierflecken erzeugten Rauschens behindert.
Und schliesslich kommt hinzu, dass in Fraktur gesetzte Texte orthographisch keineswegs einheitlich sind und sich mit den üblicherweise implementierten modernen Wörterbüchern und Rechtschreibeprüfungen natürlich nicht erfassen lassen. Ohne Hilfe von Sprachhistorikern sind die Programmierer hier verloren.
Das Problem der Frakturtexterkennung galt lange Zeit als unlösbar. Entsprechend gross ist nun der Nachholbedarf. Zum Einsatz kommt FineReader XIX bereits in einer Initiative im "Projekt Gutenberg". "Gemeinsam an Gutenberg arbeiten" ("GaGa") stellt die Rohdaten der Texterkennung ins Internet. Freiwillige Mitarbeiter übernehmen dann das Korrekturlesen. Die Ergebnisse werden in die "Gutenberg"-Sammlung aufgenommen. Und die "Neue Zürcher Zeitung" leistet sich zu ihrem 225jährigen Bestehen ein Grossprojekt: Sämtliche Ausgaben seit der Zeitungsgründung (über 2 Millionen Seiten) sollen digitalisiert werden.
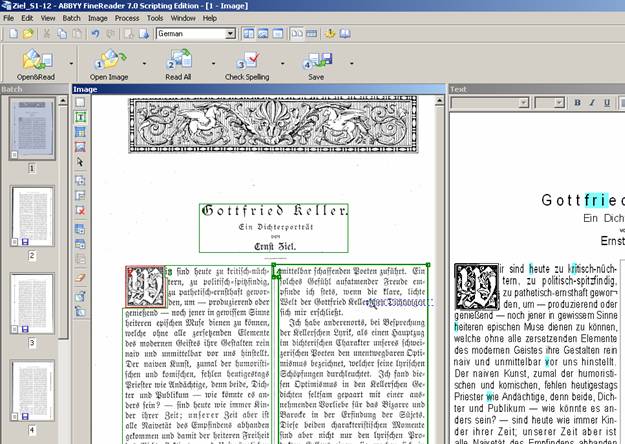
FineReader XIX im Praxistest
Um das Programm zu testen, haben wir drei Zeitschriften- und einen Zeitungstext in deutscher Sprache erfasst. Es handelt sich um literarische Rezensionen, die zwischen 1854 und 1885 erschienen sind. Eingelesen wurden nicht die Originaldokumente, sondern Zwischenmedien (Fotokopien über Scanner bzw. unter professionellen Bedingungen hergestellte Digitalfotos als Dateien); gescannt wurde mit einer relativ hohen Auflösung von 600 dpi. Die Zeichenerkennung wurde trainiert.
Die Vorlagen sind von unterschiedlicher Qualität (vgl. Abb. 2-4)
Bsp. (1): Vorlage von sehr guter Qualität, normale Schrift (ca. 10 pt), sauberer Druck
Bsp. (2): Vorlage von guter Qualität, kleine Schrift (ca. 9 pt), leicht verschmutzte Typen, geringe Papierverschmutzung (vereinzelt Fliegendreck), Zeilen eng gesetzt (dadurch Überschneidung von Unterlängenbereich und Oberlängenbereich der Folgezeile), saubere Kopie
Bsp. (3): Vorlage von schlechter Qualität, kleine Schrift (ca. 6 pt), leicht verschmutzte Typen, Papier vergilbt und verfleckt, Rückseite bedruckt und stark durchscheinend, ausserdem Bildverzerrungen in Problembereichen (Papierfaltung)
Qualität der Texterkennung
(1) 2,5 Fehler / 1000 Zeichen
(2) 2,8 Fehler / 1000 Zeichen
(3) 21 Fehler / 1000 Zeichen
Nicht berücksichtigt wurden Fehler bei Schriftwechsel (Antiqua statt Fraktur), Fehler bei Anführungszeichen, sowie I/J-Fehler (Graphem-Identität der Zeichen in Fraktur).
Wie zu erwarten war, kam die Texterkennung mit der unsauberen Vorlage von Beispiel (3) nur schlecht zurecht. Die eingeschaltete Fleckenentfernungsfunktion konnte wenig ausrichten. Die Störung durch Rauschen war so stark, dass die Texterkennung trotz Training an vielen Stellen kapitulierte. Auch an sich unproblematische Zeichen wurden nicht oder nur falsch erkannt. Die gelieferten Textdaten waren für den vorgesehen Zweck unbrauchbar, ihre Nachbearbeitung erschien als nicht sinnvoll. Der Zeitaufwand hätte den Aufwand einer manuellen Erfassung durch Eintippen überstiegen. Auf das Testen von Vorlagen, die in einem noch schlechteren Zustand sind als Beispiel (2), wurde folglich verzichtet.
Allerdings muss das unbefriedigende Ergebnis relativiert werden: 2,1 Prozent sind rein arithmetisch betrachtet noch immer eine relativ kleine Fehlerquote. Und vor allem wäre das Ergebnis auch bei einem Dokument mit Antiquaschrift kaum besser ausgefallen.
Deutlich besser präsentieren sich die Resultate der Beispiele (1) und (2). Die Fehlerquote liegt hier deutlich unter einem halben Prozent. Dieses Resultat beurteilen wir als gut.
Beurteilungskriterien und praktischer Nutzen
Unsere Anforderungen beruhen zum einen auf der langjährigen Erfahrung, die wir mit manueller Erfassung durch Eintippen gesammelt haben. Gegenüber diesem Verfahren soll der Einsatz von OCR einen Effizienzgewinn erbringen oder zumindest konkurrenzfähig sein. Zum andern ergeben sich unsere Anforderungen aus dem Verwendungszweck: Da wir die gescannten Dokumente teilweise veröffentlichen, gilt für die Enddaten eine absolute Nulltoleranz.
Geht man von diesen Voraussetzungen aus, verstehen wir unter "gut", dass die Texterkennung das Qualitätsniveau einer durchschnittlichen Schreibkraft erreicht. Als nur "genügend" stufen wir eine Texterkennung ein, bei der die Nachbearbeitung der Rohdaten den Aufwand des Eintippens nicht übersteigt. "Gut" bedeutet also zugleich auch, dass die Anschaffungskosten für die Software durch eingesparte Arbeitsstunden für das Eintippen amortisiert werden können.
Für die Beurteilung der Wirtschaftlichkeit reicht aber die vorgenommene Testserie nicht aus. Überdies hängt diese natürlich auch von der verarbeiteten Textmenge ab.
Konkurrenzlos und praxistauglich
FineReader XIX ist unseres Wissens die einzige zur Zeit auf dem Markt erhältliche Texterkennungssoftware für Frakturschriften. "FrOCR", mit dem die "Digitale Bibliothek" u. a. "Meyers Großes Konversationslexikon 1905-1909" realisiert hat, ist weder frei käuflich noch als Freeware ('Opensource') erhältlich.
Angesichts der beschriebenen Problemlage ist die Leistungsfähigkeit des Programms erstaunlich. Auch bei hohen Anforderungen kann die Erkennungsqualität als gut bezeichnet werden. Es handelt sich um keine Laborlösung, die eine komplizierte professionelle Vorbehandlung der Vorlagen oder eine projektbezogene Nach- und Umprogrammierung verlangt, sondern um eine wirklich ausgereifte und praxistaugliche Endnutzer-Lösung, die kein spezielles Knowhow verlangt.
Nach Angaben des Herstellers werden ausser der deutschen vier weitere Erkennungssprachen unterstützt. Diese Universalität scheint aber nicht um den Preis oberflächlicher Verallgemeinerungen linguistischer Daten und Erkennungsparameter erkauft worden zu sein.
Eingeschränkt wird die Erkennungsqualität selbstverständlich durch unsaubere Vorlagen. Da diese Einschränkung für Texterkennung im allgemeinen gilt, ist sie für die Beurteilung des Programms aber nicht von Belang.
Bequeme Bedienung
Das Programm ist klar strukturiert, intuitiv verständlich und einfach zu bedienen. Es verfügt über eine grosse Flexibilität und einen guten Funktionsumfang.
Die Stapelverarbeitung erleichtert die Bearbeitung von Dokumenten mit vielen Seiten.
Die Prozesse lassen sich Schritt um Schritt oder in einem Zug ausführen. Etliche Parameter können reguliert werden. Nachträgliche Anpassungen während des Prozesses (Einfügen vergessener Scans, Umstellen von Erkennungsblöcken oder ganzer Scansequenzen, Neuerkennen von Einzelteilen usw.) sind möglich.
Verbesserungsmöglichkeiten
Eine Konvention im Fraktursatz besteht darin, dass auftretende Fremdwörter in Antiqua gesetzt wurden. Da die Texterkennung aber nur Fraktur kennt, kann sie diese Wörter natürlich nicht lesen. Zu wünschen wäre, dass die Texterkennung mit dieser Konvention vertraut gemacht würde. Es handelt sich ja im Grunde um nichts anderes als um eine spezielle Form der Auszeichnung - durch Schriftwechsel statt durch Kursivierung oder Sperrung.
Auch wenn das Zulassen von verschiedenen Schriften innerhalb eines Dokumentes technisch sehr heikel sein dürfte, wäre es hier in Kombination mit einer präzisen Regel realisierbar. Das Zulassen von Antiqua-Formen müsste strikt an eine vordefinierte Liste von Wörtern gebunden werden.
Eine weitere Verbesserungsmöglichkeit betrifft das Trainieren der Zeichenerkennung.
Da man bei diesem Prozess in schneller Folge vorgeschlagene Zeichenzuweisungen bestätigt, kann schnell einmal das Bestätigen eines falschen Zeichens unterlaufen. Um die kontraproduktive Auswirkung der falsch trainierten Zuweisung zu verhindern, muss diese rückgängig gemacht werden können. Die entsprechende Funktion ist zwar vorhanden. Doch sie verfügt über einen viel zu kleinen Speicher, so dass sich eine falsch trainierte Zuweisung, wenn man sich ihrer bewusst wird, oft schon nicht mehr rückgängig machen lassen.
Links
Testbericht einer IT-Dienstleistungsunternehmung
Abb. 1: Abby FineReader XIX
Bsp. (1)

Bsp. (2)

Bsp. (3)
